
In this tutorial, I’ll show you my favorite workflow for deploying database-driven web apps. It’s meant for developers who want to go full-stack on their side projects without having to set up and maintain a complex multi-service infrastructure.
We’ll deploy a very rudimentary web app written in Node.js and Express. It allows visitors to write and save notes, and to read previously written notes. The data is stored in a MongoDB database. We’ll use GitHub Actions to create a CI/CD workflow that deploys our app on AWS Lambda.
The focus is on simplicity, pragmatism and cost saving. Since AWS and MongoDB have very generous free tiers, you can follow along free of charge. Remember, though, to undeploy the application afterwards if you don’t want to end up paying a few cents. Since your application will be publicly available, its usage can theoretically pass the free tiers in the long run. However, if you intend to extend this application for your own purposes, I can recommend this setup as being very affordable for a website with moderate traffic.
You can find all the code for this tutorial on our GitHub account.
Prerequisites
You’ll need a few things to build the app. Make sure you have Node and Docker installed on your system. To install Node, you can use the Node Version Manager (nvm) (see some instructions here). For Docker, install the latest version of Docker Desktop for your operating system.
Note that we’ll use Docker to run an instance of MongoDB on our machines. Alternatively, you can also manually install the MongoDB Community Edition. You can find some instructions here.
You’ll also need to have accounts at GitHub, MongoDB, and Amazon Web Services (AWS). When registering on AWS, you have to enter a credit card number. As mentioned above, taking the steps in this tutorial won’t exceed the free tier.
Some previous knowledge in Node and Express might be helpful.
Local Develpoment
Okay, let’s get started. We first need an empty folder with a new package.json file. You can create one if you execute npm init.
We’ll need to install the following dependencies:
- express, to react to HTTP requests from the client side
- mongoose, to communicate with our MongoDB database
- aws-serverless-express, for AWS Lambda to be able to invoke our application
- concurrently (as dev dependency), to execute npm scripts in parallel
Run the following command to install them:
npm install --save express mongoose aws-serverless-express && npm install --save-dev concurrently
1. MongoDB and mongoose
Since we use a MongoDB database to store our data in, it’s helpful for development to have a database instance running on our local machine. That’s where we use the latest mongo Docker image. If you have Docker installed on your machine, this is as easy as typing docker run mongo in your terminal. The image gets pulled from dockerhub and starts in a new container. If you’re not familiar with Docker, that’s okay. All you need to know is that there’s a MongoDB instance running on your computer that you can communicate with.
For our app to communicate with the database, we need to initialize a connection. We do that in a new file named mongoose.js. Mongoose is the library that helps us do the MongoDB object modeling:
// mongoose.js
const mongoose = require("mongoose");
const uri = process.env.MONGODB_URL;
let connection;
const connect = async () => {
try {
connection = await mongoose.createConnection(uri, {
useNewUrlParser: true,
useFindAndModify: false,
useUnifiedTopology: true,
bufferCommands: false, // Disable mongoose buffering
bufferMaxEntries: 0, // and MongoDB driver buffering
});
return connection;
} catch (e) {
console.error("Could not connect to MongoDB...");
throw e;
}
};
function getConnection() {
return connection;
}
module.exports = { connect, getConnection };
This file exports an object with two functions. connect() creates a connection to a MongoDB in the location that we specify in an environment variable. The connection is being stored in a variable called connection. getConnection() simply returns the connection variable. You might wonder why we don’t just return the connection variable itself. This is due to the fact that Node.js caches required modules after they’re first loaded. Therefore, we use a function to pull out the latest connection variable from our mongoose.js module.
Now that our app will be able to connect to the database, we’ll also want to store data in it — more specifically, the notes that we can write in our user interface. Therefore, we’ll create a data model for our notes. This is done in a new file named Notes.js inside a models folder:
// models/Notes.js
const mongoose = require("mongoose");
const { getConnection } = require("../mongoose");
const conn = getConnection();
const Schema = mongoose.Schema;
module.exports = conn.model(
"Note",
new Schema({ text: { type: String, required: true } })
);
Here, we pull out the current connection from our mongoose.js module and register a model called Note onto it. It has a very basic schema which only contains a required property text of type String. With this model, we can construct documents that we store in our database.
2. Express application
Next, we create a simple Express application. Create a file called app.js in your project root. It has the following content:
// app.js
const express = require("express");
const app = express();
app.use(express.urlencoded({ extended: false }));
app.get("/", async (req, res) => {
try {
const Note = require("./models/Note");
const notes = await Note.find({});
return res.status(200).send(
`<!DOCTYPE html>
<html lang="en">
<head>
<title>My Notes</title>
<style>
html {
text-align: center;
background-color: #93c5fd;
font-family: "Segoe UI", Tahoma, Geneva, Verdana, sans-serif;
color: white;
font-size: 2rem;
}
textarea {
resize: none;
border: 2px solid #9ca3af;
border-radius: 4px;
background-color: #f3f4f6;
padding: 0.5rem;
width: 90%;
}
button {
padding-left: 2rem;
padding-right: 2rem;
padding-top: 7px;
padding-bottom: 7px;
background-color: #f3f4f6;
border: 2px solid #9ca3af;
color: #4b5563;
border-radius: 4px;
}
p {
border-bottom: 2px solid;
padding: 1rem;
text-align: left;
}
</style>
</head>
<body>
<h1>My Notes</h1>
<form method="POST">
<textarea required name="text" rows="5" cols="50" placeholder="Create a new note"></textarea>
<button type="submit">Save</button>
</form>
${notes.map((n) => `<p>${n.text}</p>`).join("")}
</body>
</html>`
);
} catch (e) {
return res.send(e);
}
});
app.post("/", async (req, res) => {
try {
const Note = require("./models/Note");
const note = new Note(req.body);
await note.save();
return res.send("Note saved. <a href=''>Refresh</a>");
} catch (e) {
return res.send(e);
}
});
module.exports = app;
As I said, the application is very rudimentary and serves as a demo. First, we initiate an Express app. Then we tell it to parse incoming request bodies with the built-in, urlencoded middleware for us to be able to work with submitted form data. The app has two method handlers for requests on the application root:
-
app.get("/", ...)handles HTTP GET requests. It’s invoked when our users load the page. What we want to show them is a simple page where they can type in a note and save it. Also, we want to display previously written notes. In the callback function of the request handler, we require ourNotemodel. The model has to be required inside the callback function of our POST request handler, since it needs a current database connection – which might not exist when theapp.jsfile gets first loaded. Then, we apply thefindmethod to receive all notes from the database. This method returns a promise. Therefore, we wait for it to resolve. Last but not least, we use thesendmethod of the response object (res) to send a string back to the client. The string contains HTML syntax that the browser renders into actual HTML elements. For each note in our database, we simply add a paragraph element containing its text.This is the point where you can transform this very rudimentary example into a beautiful user interface. You’re free to choose what to send to the client. This could, for example, be a fully bundled client-side React application. You might also choose a server-side–rendered approach — for example, by using an Express view engine like handlebars. Depending on what it is, you might have to add more routes to your application and serve static files like JS bundles.
-
app.post("/", ...)handles HTTP POST requests. It’s invoked when users save their notes. Again, we first require ourNotemodel. The request payload can be accessed through the body property of the request object (req). It contains the text our users submit. We use it to create a new document and save it with thesavemethod provided by Mongoose. Again, we wait for this asynchronuous operation to finish before we notify the user and give them the possibility to refresh the page.
For our app to actually start listening to HTTP requests, we have to invoke the listen method provided by Express. We’ll do this in a separate file named dev.js that we add to our project root:
// dev.js
const app = require("./app");
const { connect } = require("./mongoose");
connect();
const port = 4000;
app.listen(port, () => {
console.log(`app listening on port ${port}`);
});
Here, we invoke the connect function from our mongoose.js file. This will initiate the database connection. Last but not least, we start listening for HTTP requests on port 4000.
It’s a little cumbersome to start the mongo Docker image and our app with two separate commands. Therefore, we add a few scripts to our package.json file:
"scripts": {
"start": "concurrently 'npm:mongoDB' 'npm:dev'",
"dev": "MONGODB_URL=mongodb://localhost:27017 node dev.js",
"mongoDB": "docker run -p 27017:27017 mongo"
}
mongoDB initiates a MongoDB instance and maps the container port 27017 to port 27017 of our local machine. dev starts our application and sets the environment variable MONGODB_URL that’s being loaded in the mongoose.js file to communicate with our database. The start script executes both scripts in parallel. Now, all we need to do to start our app is run npm start in the terminal.
You can now load the application by visiting http://localhost:4000 in your browser.
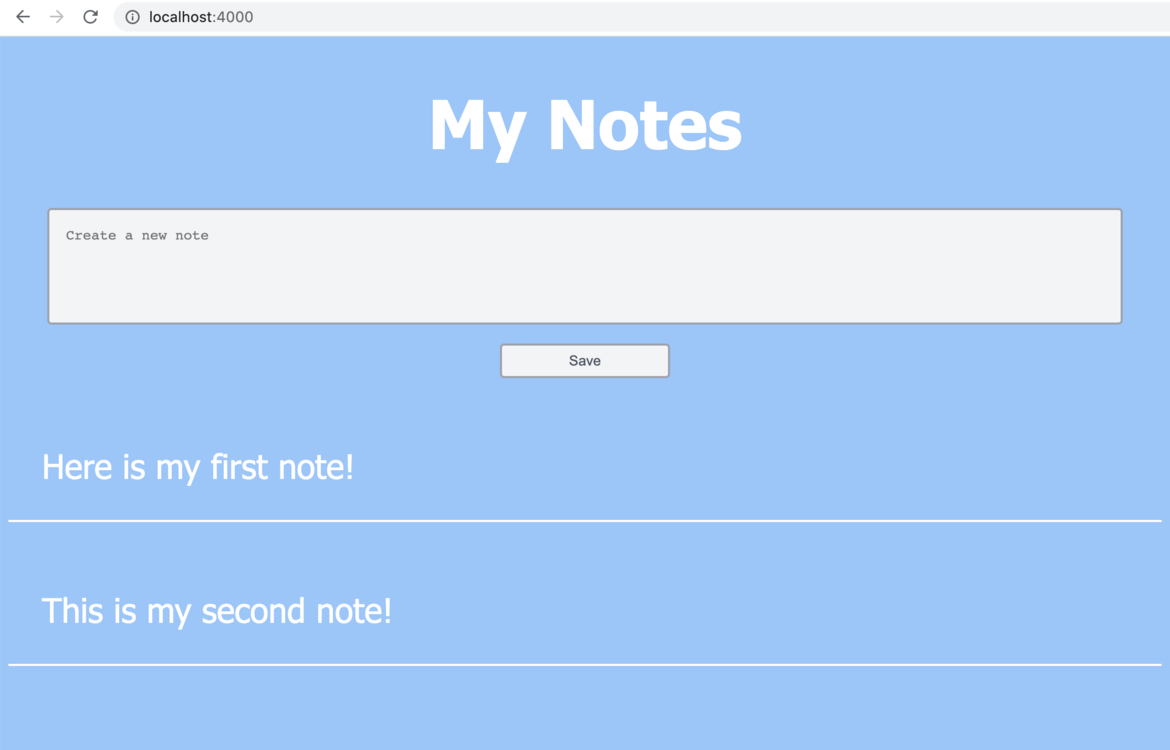
Deployment
Now it’s time to deploy our app. We’ll do that using Lambda functions on AWS, MongoDB Atlas, and AWS API Gateway.
1. What are Lambda functions and why are we using them?
Lambda functions are a way to execude code in response to HTTP requests without needing to maintain a server. They only run on demand, which means that, if nobody calls your service, you don’t have to pay for server time. On the other hand, if many people call your service, AWS automatically scales up and more Lambda instances initiate.
As the name suggests, Lambda functions are functions, and you can fill them with whatever you want. There’s only one exception: your code should not have a state, since a Lambda instance shuts down once it’s not being executed anymore.
We’ll wrap our entire application inside a Lambda function and deploy it on AWS Lambda. AWS Lambda has a very generous, unlimited free tier which includes one million free requests and 400,000 GB seconds per month! So you can safely experiment with the service and deploy several Lambda functions without having to pay for it. Just remember to delete the functions if you don’t want to use them anymore.
2. Creating an AWS Lambda function
Now, log in to your AWS management console and navigate to AWS Lambda. Under the Functions section, click Create Function. Before doing so, it’s important that you’ve specified the region you want to have your service deployed to. On a desktop computer, you can select a region in the upper right-hand corner of your management console.
Choose Author from scratch and give your function a name. I’ll call it express-lambda-example. Under runtime, select Node.js 12x and then create the function. You’ll see a window that looks like this:
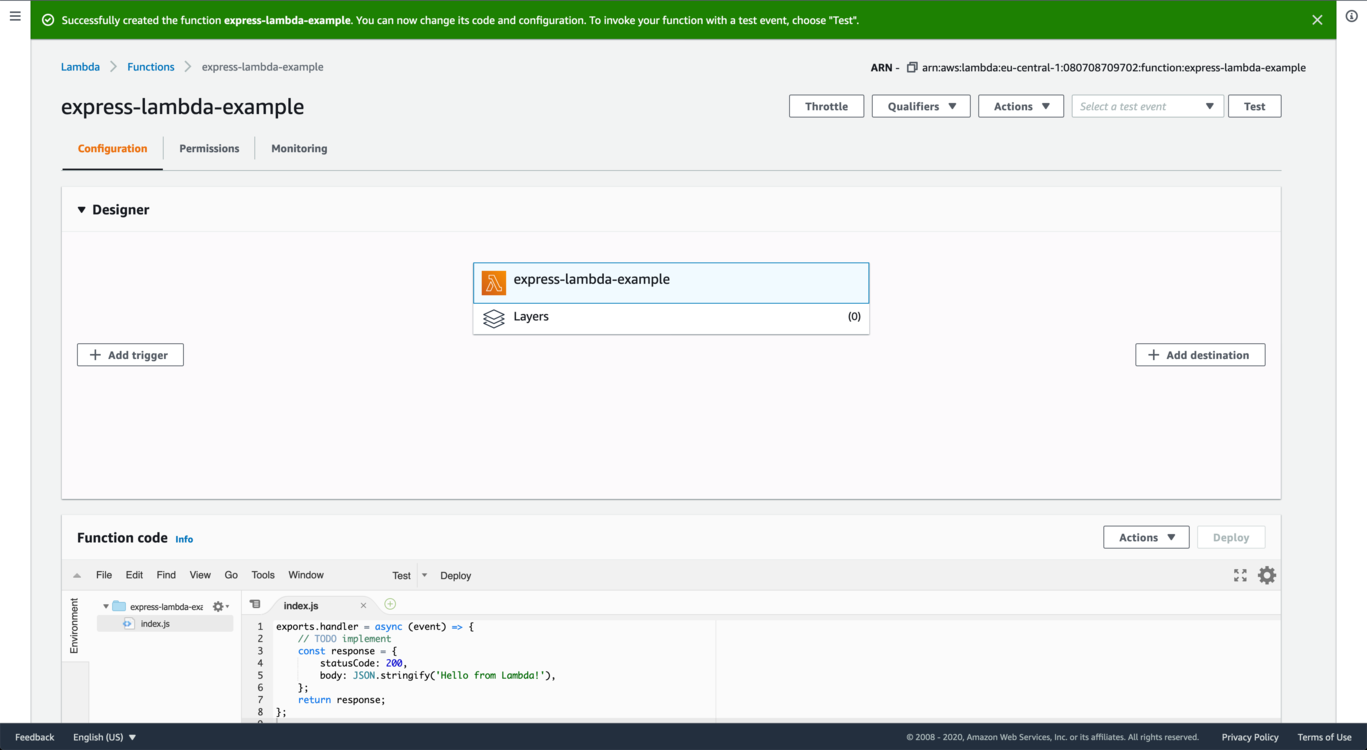
Our Lambda function already contains some test code. You can ignore this, since we’ll override it later. If you scroll down the page, you’ll see a section called Environment variables. Remember that, earlier in our local dev script, we defined a variable called MONGODB_URL? We’ll have to create the same variable here for our Lambda instances to be able to communicate with our database.
However, we don’t have a database up and running. We don’t want to use our local machines for that purpose. That’s why we’ll create a free tier cluster on MongoDB Atlas.
3. Setting up a MongoDB Atlas cloud service
To create a free tier cluster, create an account on mongodb.com. During the registration process, you’ll be asked to choose a cluster type. Choose a free Shared Cluster. The next step is to give your project a name. In addition, you can select your preferred programming language.
In the next step, you can pick a cloud provider and a region. Since we already use AWS for our Node.js application, I recommend you select that and, if possible, the same region you previously picked on AWS. In the next section, you can decide what tier you want to use. Pick the M0 Sandbox tier. MongoDB doesn’t recommend using this tier in production environments, but for starters, it will provide everything you need.
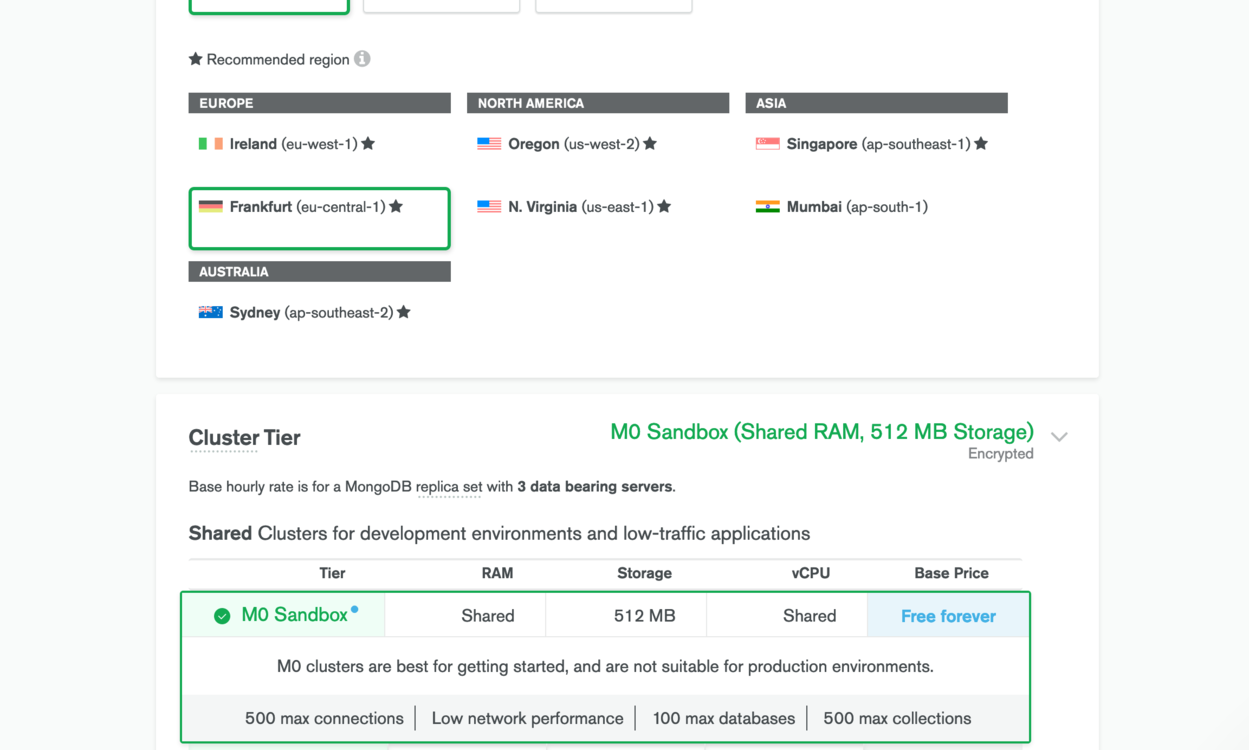
After a few minutes, our cluster is ready to be used. All that’s missing now is access to it. Click on Database Access in the menu and create a new user. The authentication method is password. Give the user read and write permissions. Once you’ve done that, we need to whitelist an IP addresses that can access our database. You can do that under the section Network Access.
Unfortunately, we don’t and we can’t know the IP of each of our Lambda instances that will try to connect to our cluster. Therefore, we’ll whitelist any IP address by adding 0.0.0.0/0. Note that this is not recommended if you have sensitive data and want to ensure high data protection. Our cluster is now only protected by the credentials we gave to our database user. Setting up a Peering Connection would be a possible solution to this problem.
Now, go back to your cluster and click Connect. In the modal window that pops up, click on Connect your application. Then, select Node.js version 2.2.12 or later and copy the connection string. Back in our Lambda function console on AWS, create a new environment variable named MONGODB_URL and paste in the connection string. Make sure to replace the placeholders in the string with the credentials of your database user and the name of your database.
4. Make your app ready for AWS lambda
For AWS Lambda to be able to invoke our application, we have to set up a new entry script, similar to what we’ve done in the dev.js file. We will call it index.js, and it has the following content:
// index.js
const awsServerlessExpress = require("aws-serverless-express");
const { connect } = require("./mongoose");
let connection = null;
module.exports.handler = async (event, context) => {
context.callbackWaitsForEmptyEventLoop = false;
if (connection === null) connection = await connect();
const app = require("./app");
const server = awsServerlessExpress.createServer(app);
return awsServerlessExpress.proxy(server, event, context, "PROMISE").promise;
};
Here, we use the aws-serverless-express library. It basically has the same functionality as the listen method in dev.js. It allows our application to handle client requests in a Lambda environment.
Now, there’s one important thing to note concerning our lambda.js file. The handler function is being executed every time a Lambda function is invoked. Everything outside this function is initiated once a Lambda container starts, and might persist across multiple Lambda calls. This is the reason why we store our MongoDB connection object in the global scope of the file. Every time the handler function runs, it checks if a connection has already been initiated. If so, the function reuses it instead of reconnecting to the database every single time. This is very important, since it saves a lot of execution time. For the connection to persist across multiple calls, we need to set context.callbackWaitForEmptyEventLoop to false. You can read more about this functionality here.
5. Deploy to AWS Lambda with GitHub Actions
The next step is to use GitHub Actions to create a CI/CD workflow. This means that every time we push code changes to a GitHub repository, we want a pipeline to be triggered. The pipeline automatically takes care of updating our Lambda function on AWS. This process has been greatly described by Jakob Lind in his article “How to set up an AWS Lambda and auto deployments with Github Actions”. I’ll just briefly summarize the main parts.
For GitHub to set up and iniate the workflow, we create a file called deploy.yml in the path /.github/workflows. It contains the following YAML code:
# /.github/workflows/deploy.yml
name: deploy to lambda
on:
push:
branches:
- main
jobs:
deploy:
name: deploy
strategy:
matrix:
node-version: [12.x]
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v1
- name: Setup Nodejs
uses: actions/setup-node@v1
with:
node-version: ${{ matrix.node-version }}
- name: npm install
run: npm ci --production
- name: zip
uses: montudor/action-zip@v0.1.1
with:
args: zip -qq -r ./app.zip ./
- name: push to lambda
uses: appleboy/lambda-action@master
with:
aws_access_key_id: ${{ secrets.AWS_ACCESS_KEY }}
aws_secret_access_key: ${{ secrets.AWS_SECRET_KEY }}
aws_region: eu-central-1
function_name: express-lambda-example
zip_file: app.zip
The file tells GitHub Actions to execute a job with the name deploy on every push to the main branch of your repository. For me, it’s very useful to restrict this to the main branch only. So, you can safely push to your development branches without unwanted code being deployed.
The deploy job simply installs all necessary libraries, zips the whole project up, and pushes it to AWS Lambda. Note that the YAML file needs to access AWS access keys through environment variables: AWS_ACCESS_KEY and AWS_SECRET_KEY. You can generate those keys by creating a new user in your Identity and Access Management console on AWS. Once you have the keys, you need to save them as environment variables in your GitHub project settings under Secrets.
All you need to do to get your application ready on AWS Lambda is to commit your code and push it to the main branch of your GitHub repo.
6. Make our app accessible with AWS API Gateway
Now we have our application ready to be used in a live environment. However, we don’t have the means to access it through the Web. This is what we do next with AWS API Gateway. Note that API Gateway also has a free tier. However, this one is limited to 12 months only.
In your AWS console, navigate to the API Gateway service and click Create API, select REST API, give it a name and save it.
To connect API Gateway to our Lambda function, we create a new method that redirects any HTTP request forward to our Lambda function. So, in the Actions drop-down menu, select Create Method and pick ANY. You should see a screen like the one in the image below. Make sure the box Use Lambda Proxy Integration is checked. Type in the name of your Lambda function and save.
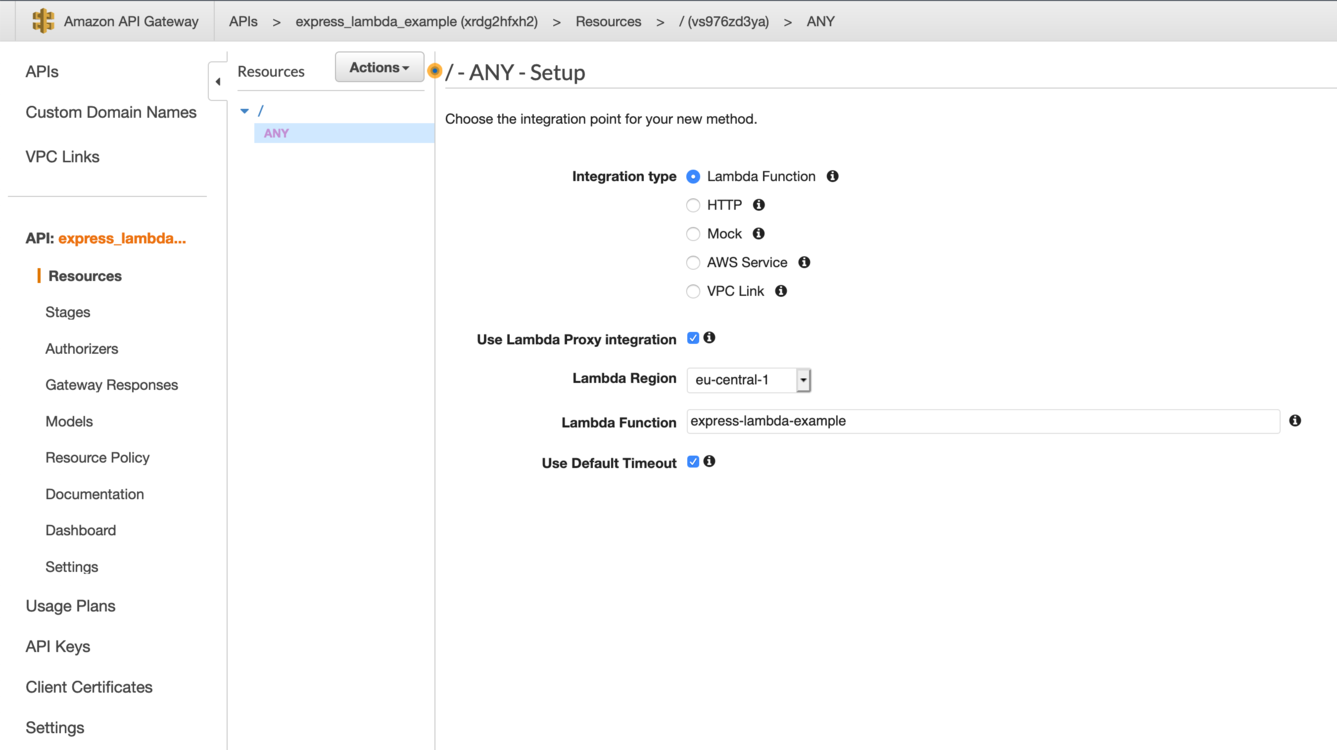
Next, we have to set up a Lambda proxy integration. This basically means that all client requests should be redirected to our Lambda function as they are. Therefore, we create a new resource in the Actions drop-down. In the modal window that pops up, check the box Configure as proxy resource (see below) and save.
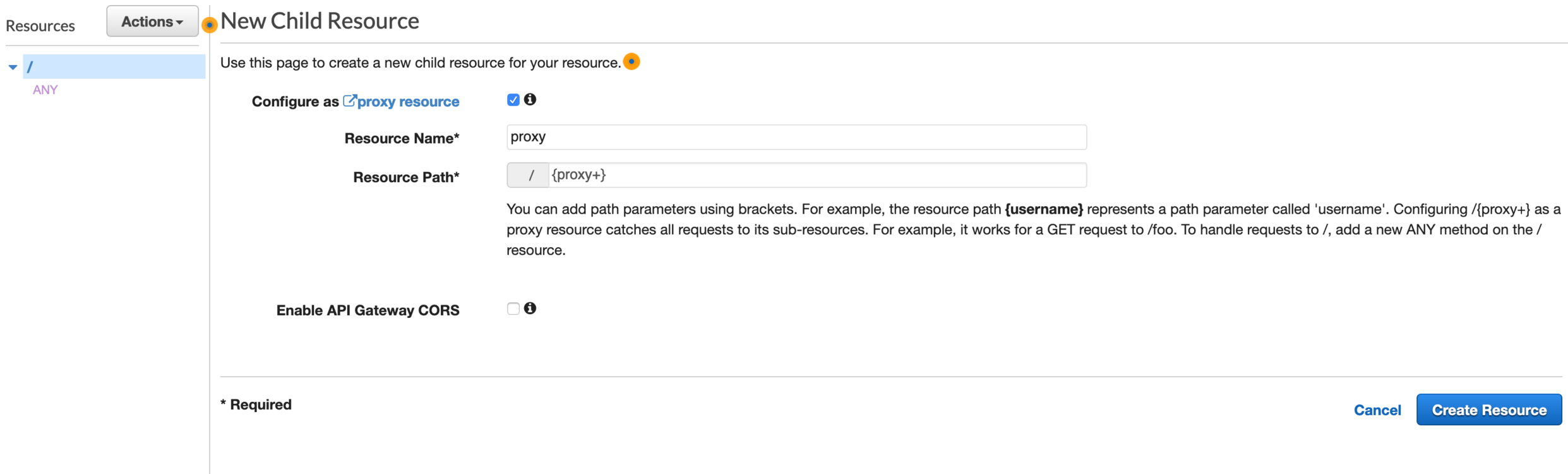
This will create another method that we have to connect with our Lambda function.
Last but not least, we deploy our API by selecting Deploy API in the Actions dropdown. In the window that pops up, pick [New Stage], give the stage a name and deploy it.
That’s it. You can access our application by clicking on the Invoke URL that you can find in the Stage Editor of your created stage. The Invoke URL is the public URL that maps to our API Gateway. Of course, you can also use custom domains to do that.
Conclusion
You see that deploying more complex applications that require a database doesn’t have to be difficult. For sure, the workflow I showed you is far from being perfect and lacks many features that large-scale applications require in the long run. But for me, it’s proven to be simple, pragmatic, and inexpensive for websites with low and moderate traffic. I used a very similar tech stack to build and deploy JSchallenger.
If you have any thoughts or comments, please reach out on Twitter: @kueckelheim.